
Some of our early customers noticed a strange quirk in Inter-1. When they fed it videos with the audio missing and asked it to read social signals, it would occasionally do something it had no business doing: quote someone. In silence, with nothing to hear, it would report that the person on screen had said "Yeah, Friday at five."
TL;DR: We found a quirk in Inter-1 — when a modality goes missing, the model hallucinates to fill the silence. Hunting it down taught us a lot about omni-modal failure.
Authors: Sid Ravi (AI Research), Patrizio Cugia (Data Engineering)
What Inter-1 does
Inter-1 is our model for reading human communication from video. You hand it a short clip and it returns a structured judgment: an overall engagement state, a set of social signals (agreement, hesitation, skepticism, confidence, and so on) each with a grounded rationale.
Inter-1 is omni-modal. It inspects the video, listens to the audio, and holistically decides what is going on.

Omni-modal models are powerful precisely because they fuse modalities. But they come with their quirks. When one modality goes missing, the model can fall back on whatever it learned during training to paper over the gap. A video with no audio is exactly that kind of gap, and "Yeah, Friday at five" was what fell into it.
The suspects
To hunt down the source of these goblins, our team turned over every stone we could find. The instinct, reasonably, was that a phrase this specific had to be somewhere in the pipeline we trained with. We went looking for it everywhere it could plausibly live.
| Where we looked | Subset scanned | What we found |
|---|---|---|
| Training corpus: weekday and datetime mentions | 30,960 records | Tuesday (118) outweighs Friday (73). "Friday at five": 0. |
| Video transcripts | 4,603 transcripts | 0 occurrences of the phrase. |
| Prior inference probes against Inter-1 | ~800 generated records | 0 occurrences. |
| Untouched storage buckets | 584 objects / 1.7 GiB | 0 verbatim hits. |
| Exhaustive log and storage phrase sweep | 194 hits | Most prompt-load or known sources. 20 inference-like. |
We focused in quickly on the post-training data since this was one of the most likely culprits. The word "Friday" was over-represented in one part of our post-training dataset, with 73 occurrences, and the weekday distribution across the corpus was genuinely lopsided.
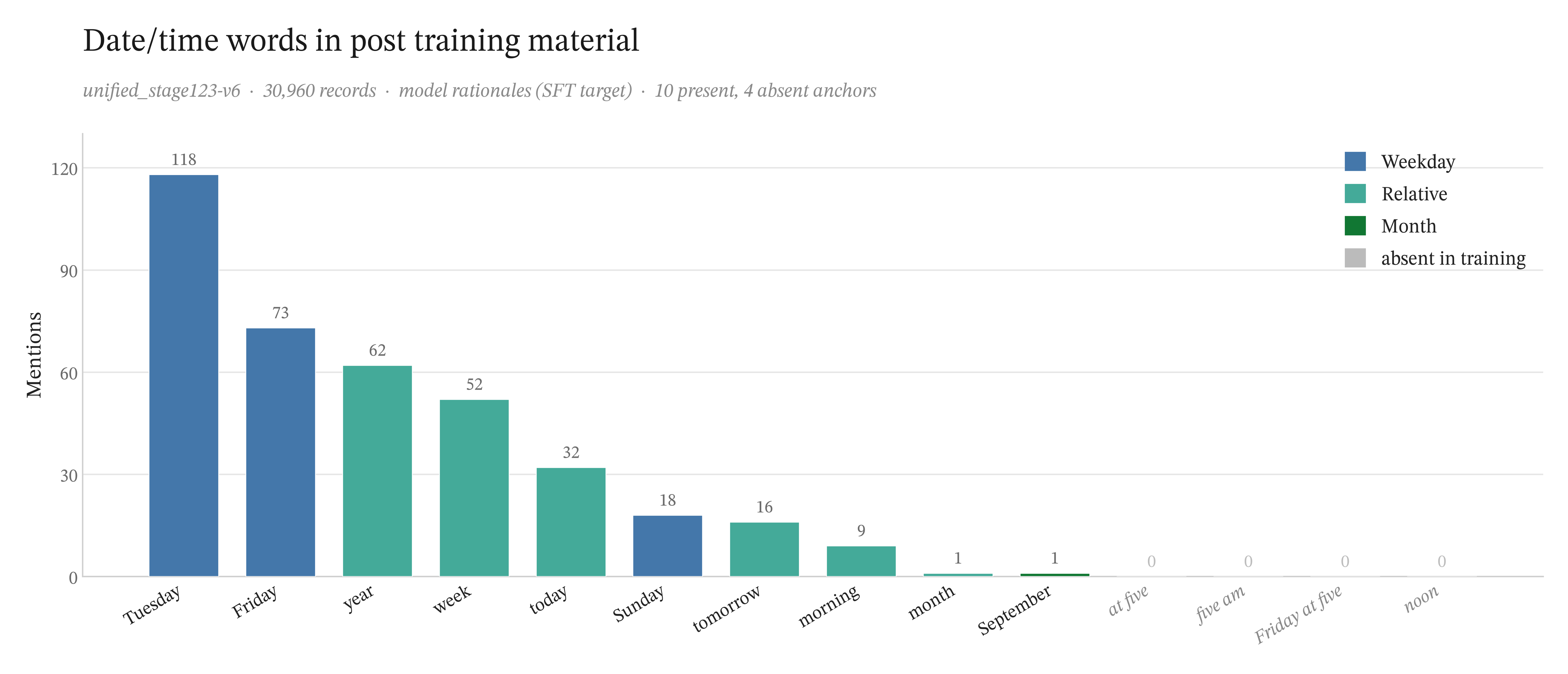
Frequency of date/time expressions in the v6 SFT rationale dataset. Tuesday (118) outweighs Friday (73); "Friday at five" and its clock-time components appear zero times.
But Friday was not even the most-mentioned day. If the model were simply echoing the most frequent day it had seen, it would be saying Tuesday. And the verbatim sentence "Yeah, Friday at five" appeared exactly zero times in the approximately 30,000-record training subset we inspected.
So we started transcribing the videos themselves. Over-representation there compounding with a missing-audio fallback was also plausible. After 4,603 transcripts and zero hits, "Yeah, Friday at five" started becoming a meme in our Slack channels.
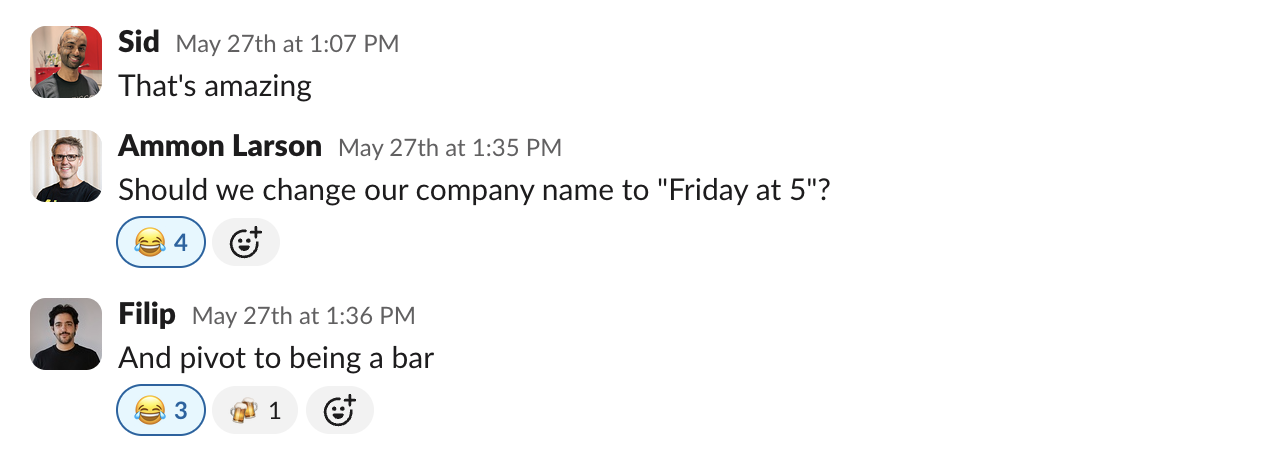
The clue that redirected us
The thing that finally turned us around was small. There was a direct mention of Friday in one signal's ontology which the model grounds itself on. Content in the context window gets a great deal of the model's attention, far more per token than a frame of silent video. That was the hint. So we started looking deeper into the harness.
We regularly auto-optimize our prompts using the GEPA algorithm, and that turned out to be the first hit. Buried in the May 2026 system prompt (internal name: inter-1 System prompt v3) was an example of what a good response looks like. This would sit in the context window on every inference call so the model picks up the expected format in-context:
other_1: "So you're saying the deadline is Friday?" subject: "Yeah, Friday at five. We've got the whole team lined up for it."
Over three weeks of traffic since we moved to this prompt version, the phrase 150x'd in the logs we'd collected. To ablate, we also chased the boring but necessary hypothesis with our backend team — that a cache somewhere was pinning a poisoned example into requests — and traced the API path until we had ruled it out. The phrase was never cached and never learned. It had only ever existed in the prompt we wrote.
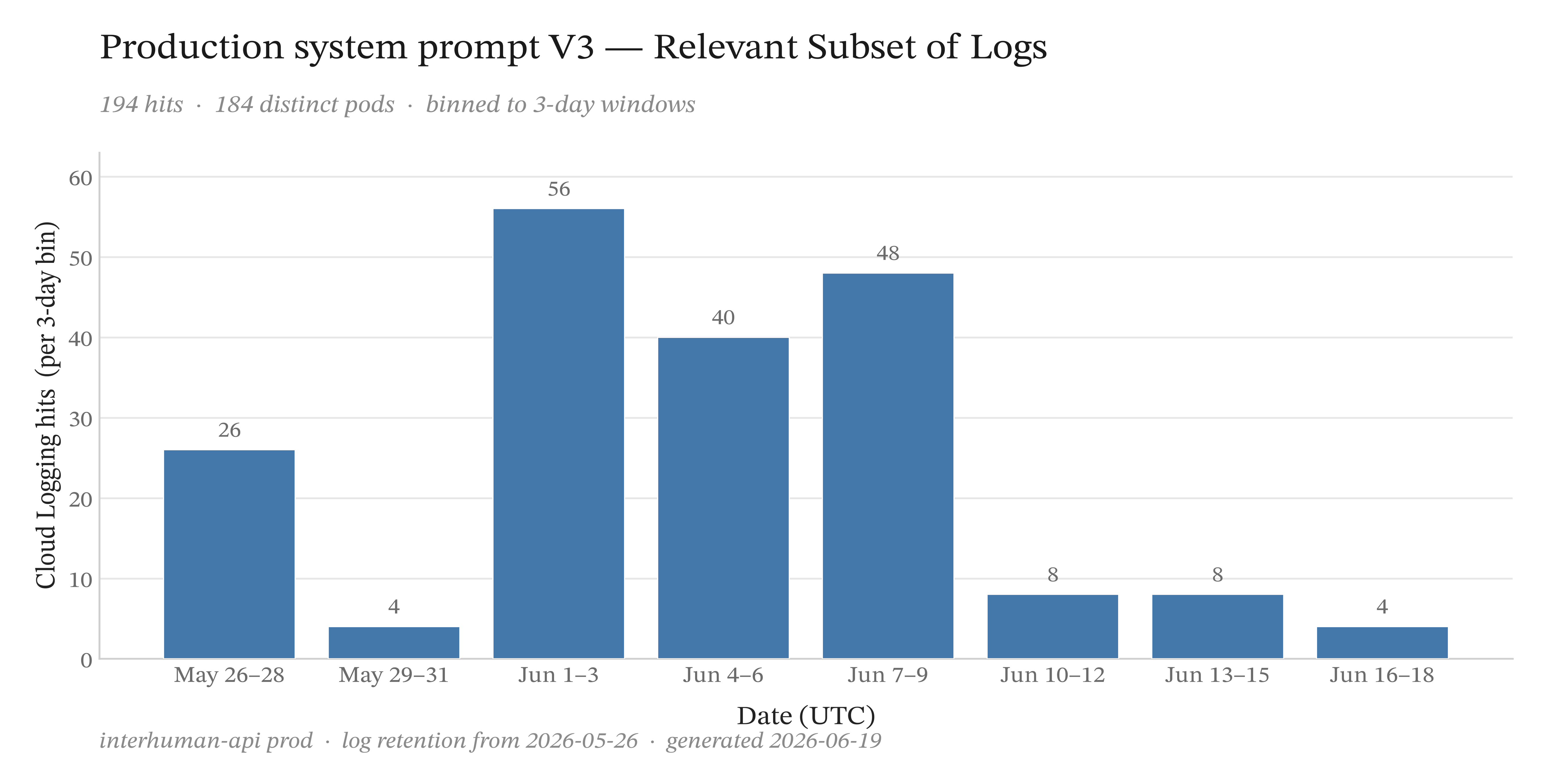
Occurrences of "Yeah, Friday at five" in production Cloud Logging (May 26 – Jun 18), binned to 3-day windows. 174 of 194 hits are system-prompt loads; 20 are model output. Volume rises from the late-May ship date of the transcript feature.
Two experiments in Interhuman Labs
Tracing the phrase to the prompt proved a strong circumstantial case. A prompt example does not force a model to read it aloud over silent video. So we took it into Interhuman Labs, our internal tool for running experiments against deployed models, and turned two separate knobs to see what actually drives the bug. Both used read-only inference against the already-deployed endpoint, and deliberately silenced nodding clips, so there was genuinely nothing to transcribe.
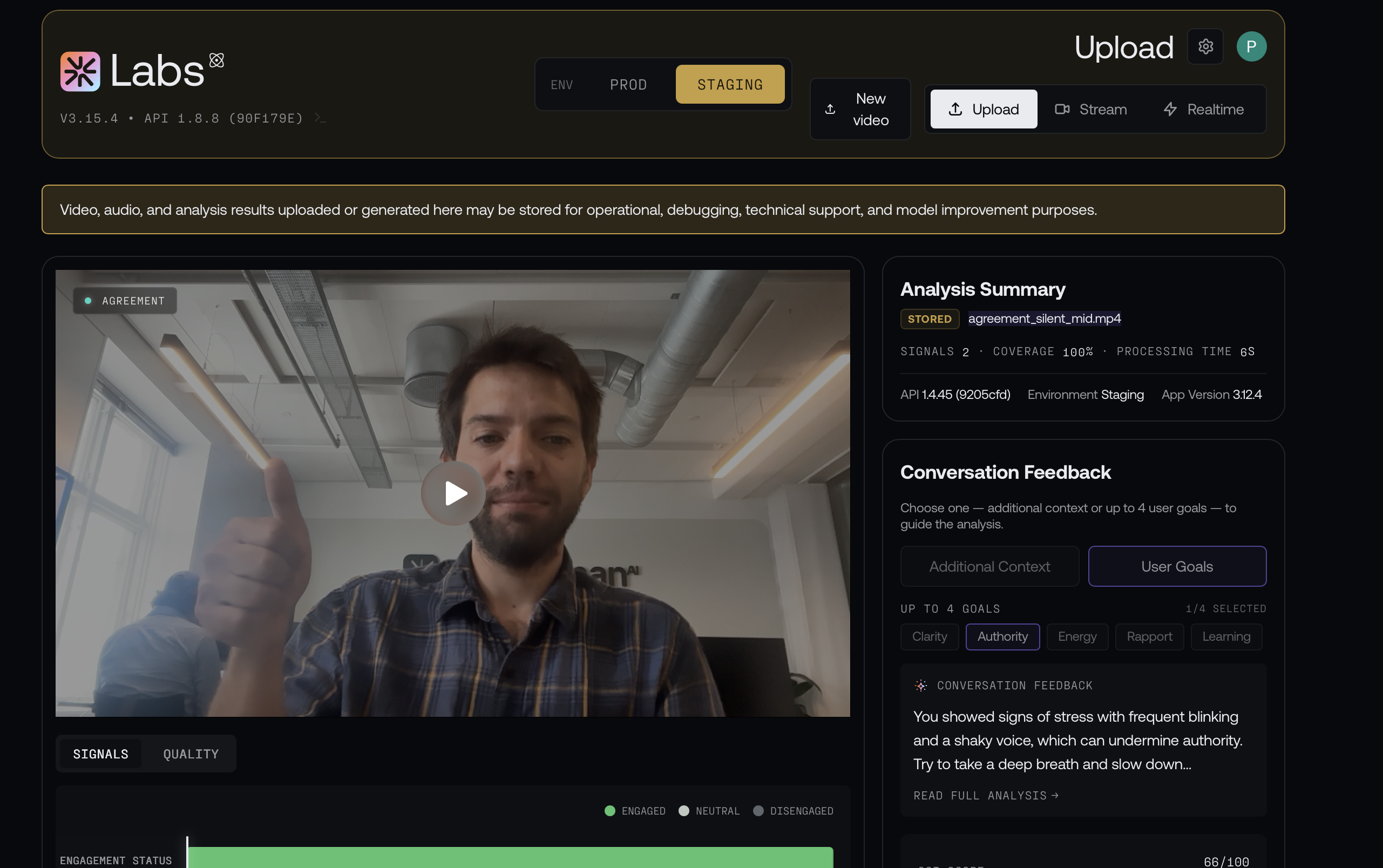
Knob one: change the word in the prompt
We held the model fixed and edited the one line in the system prompt's example. With the original "Friday at five" example in place, Inter-1 fabricated the quote in 37% of silent runs. We swapped that single line to a different day and time — "We ship on Tuesday at noon" — and ran it again. The model kept fabricating, now in 50% of runs, but the invented quote had flipped from Friday to Tuesday. That is as direct a demonstration as we could ask for that the words come at least partially from the example we wrote, not from anything the model heard or learned.
Knob two: change the model, keep the prompt
Here we held the production prompt fixed, confirming on every call that the model saw the exact goblin-bearing prompt down to the token (3,034 text tokens, identical every run). For this ablation, we swapped Inter-1 for two larger model variants we trained during the modeling stage and an earlier checkpoint of Inter-1. We ran every configuration multiple times at production temperature to measure how often each one invents speech on silence.
This is where the story turned. On a silent video, the prompt explicitly says: "if no speech is present, return an empty transcript." Here is how often each model fabricated a transcript anyway:
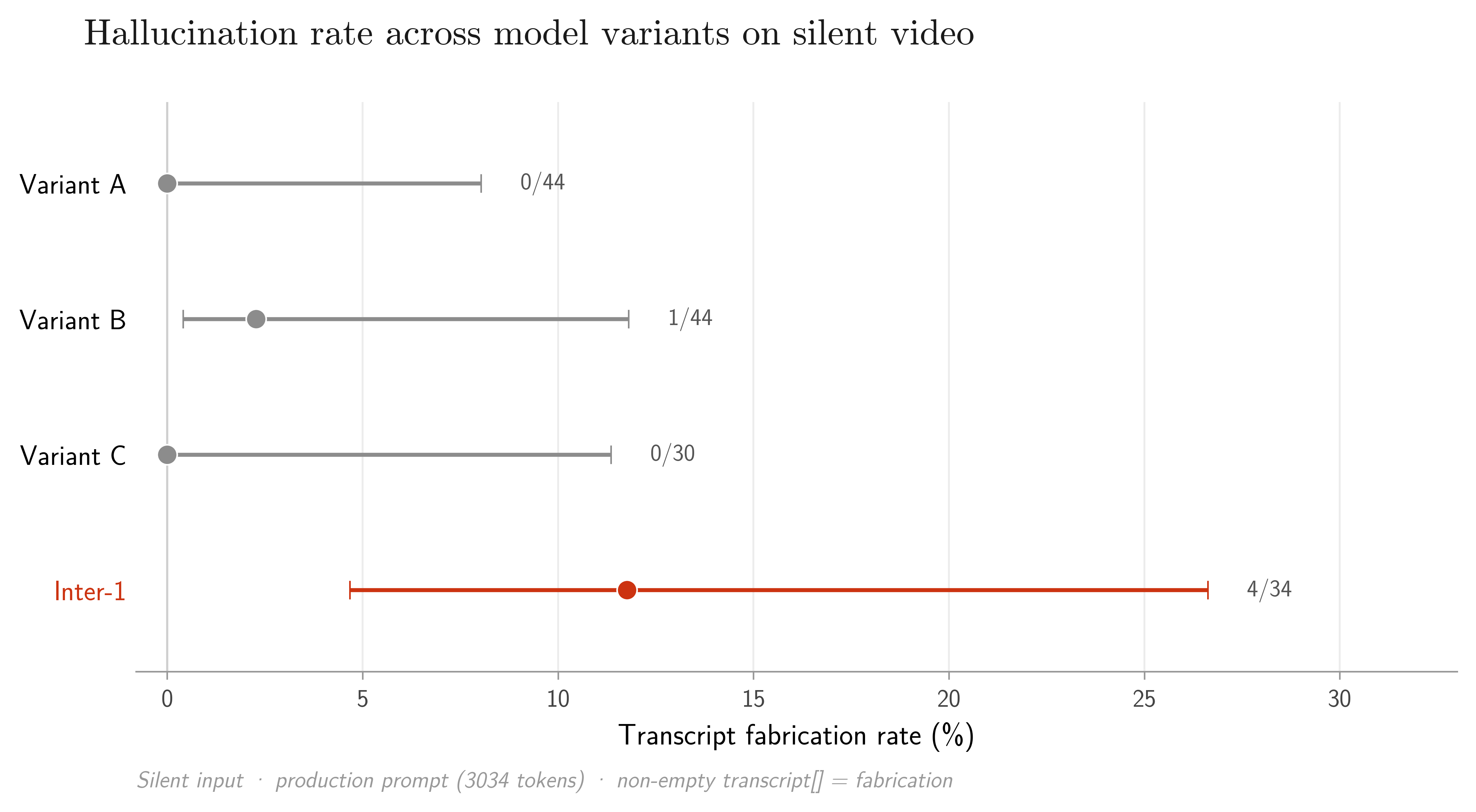
Transcript fabrication rate on silent video (non-empty transcript = fabrication), per model, under an identical 3,034-token production prompt. Dots are observed rates, whiskers are Wilson 95% confidence intervals; fractions give fabrications over valid runs. Fine-tuned Inter-1 fabricates in 4/34 runs (11.8%); the comparison models sit at 0–2%.
The larger variants were largely immune to the phenomenon. Earlier checkpoint versions of Inter-1 barely show it either. But after further post-training, it starts manufacturing speech over silence roughly one time in eight. And when Inter-1 fabricates in this condition, it does not reach for the prompt's example. It invents fresh, plausible dialogue:
"So we got the report in, finally. It's looking good. Seems to be on track. And you guys are happy with that, right?"
"Yeah! Got it. Okay, awesome. I'll definitely give that a try."
This second experiment ran in a different serving environment from the swap above — one where the backend had since layered in extra guardrails to damp the specific phrase — so the verbatim "Friday at five" largely drops out here, and what is left is the bare reflex: the model fills the silence with something, just not always the line we handed it.
Read the two experiments together and they slot into place from opposite directions. Swap the word in the prompt and the fabricated quote follows it, Friday to Tuesday, so the words are the prompt's. Hold the prompt fixed and swap the weights, and only the fine-tuned model fabricates at all, so the reflex to speak over silence is the fine-tune's. The example handed Inter-1 a script; the training gave it the compulsion to perform one. Neither alone is the bug. Together they explain it.
There is a second, subtler failure mode underneath this. Even when Inter-1 obeys the empty-transcript rule, its rationales often claim the subject spoke: "he says 'yeah,'" "asking 'Right.'" By that broader measure the gap between Inter-1 and the other models is dramatically larger.
The bug we fixed, and the one we didn't
The two halves of this story have very different lifespans. The careless example was the easy half: we hardened our prompt. To keep the goblin off real traffic in the meantime, we rolled out a guardrail that recognizes when a request arrives with zero audio tokens and suppresses the fabrication on that path.
That's why the quote now only surfaces on the specific no-audio footage that slips past it, and why reproducing it cleanly already takes a deliberately silenced clip in the Lab. But the guardrail only hides the symptom. It doesn't touch the underlying reflex — which is what the second experiment goes after, and what we're still working to fix.
The half that matters is the one the second experiment exposed: the example was never really the disease, it was the script the disease happened to recite. Post-training taught Inter-1 that an answer comes with a transcript. Every training target had one, so when the audio disappears and there is nothing to transcribe, the model would rather invent speech than report its absence. Delete the example and the model stops saying that sentence; it does not stop talking. The reflex to manufacture something was learned, and it might survive every prompt edit we make.
The bug was the easy part. The failure mode is the real subject.
The reason this phenomenon is worth a blog post is that our goblin is a particularly vivid instance of a failure mode that runs through every omni-modal model, ours included. Recent literature calls it an audio-visual "Clever Hans" effect: a model that looks grounded in a modality but is really predicting from a learned prior instead of verifying the stream it is supposed to be reading. The diagnostic that defines it silences, shifts, or swaps the audio and checks whether the model notices, and the headline result is exactly our bug, generalized. Across every model tested, they "invent audio that fits the prior but rarely deny audio that is real."
That reframes our own finding, and it is worth being precise about where the culprit lives. Our ablations are evidence that the reflex is a learned prior. The model came to expect that an answer contains speech, so on silence it confabulates speech rather than admit there is nothing there. That is the Clever Hans effect, caught in the act, on our own model. The weights are merely where the prior happens to sit. The thing worth our time is the prior itself.
And here is the part the literature has not covered yet. The published work mostly studies visual priors: a skateboarder visibly wipes out, so the model writes "thud" over silent footage; the hallucination comes from the picture. Inter-1's invented speech, on the other hand, is not cued by anything in the silent video. It is cued by what the model learned to expect, and, when a vivid example is sitting in the prompt, worded by what is nearest in its context window. The Friday-to-Tuesday swap is the proof of that second axis: change the text prior, and the fabrication's content moves with it. Training priors and prompt priors speak for the missing modality too, and those are axes a vision-only diagnostic will never catch.
That is the problem we are pointing ourselves at, and it is a genuinely hard one — specifically: making an omni-modal model treat an absent modality as missing data. The directions are promising. Teaching the model through preference pairs to prefer "there is nothing here" over a confident fabrication has been shown to fix exactly these silenced cases without taxing general performance. Decode-time methods can re-weight attention back toward the modality the model should be grounding in. We think the right answer has to defend more than the visual axis, because our own goblin proved the prompt and the training are priors too.
This is the first of what we expect to be several posts on it. The goblin we have put to bed; the failure mode behind it we have not, and we would rather tell you what we learn as we go than wait for a tidy ending.
If chasing a fake quote through four thousand transcripts, half a dozen storage buckets, your own system prompt, and finally the model's learned priors — only to decide the quote was never the interesting part — sounds like a good time, come build the next part with us. We're a passionate bunch of researchers and builders working out of Copenhagen, Denmark.
References
[1] Leng, S. et al. (2024). The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio. arXiv:2410.12787.
[2] Barański, M. et al. (2025). Investigation of Whisper ASR Hallucinations Induced by Non-Speech Audio. arXiv:2501.11378.
[3] Olsson, C. et al. (2022). In-context Learning and Induction Heads. Transformer Circuits Thread.
[4] Elhage, N. et al. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread.
[5] Tu, C. et al. (2025). Attention Reallocation: Towards Zero-cost and Controllable Hallucination Mitigation of MLLMs. arXiv:2503.08342.
[6] Liang, X. et al. (2024). Mitigating Hallucination in Visual-Language Models via Re-Balancing Contrastive Decoding. arXiv:2409.06485.
[7] Wu, H. et al. (2025). When Language Overrules: Revealing Text Dominance in Multimodal Large Language Models. arXiv:2508.10552.
[8] Wang, S. et al. (2025). Mitigating Multimodal Hallucinations via Gradient-based Self-Reflection. arXiv:2509.03113.
[9] Wen et al. (2026). When Vision Speaks for Sound. arXiv:2605.16403.
[10] Agrawal, Lakshya A., et al. (2025). "GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning." First Workshop on Foundations of Reasoning in Language Models.


